Sharf: Shape-conditioned Radiance Fields from a Single View
International Conference on Machine Learning (ICML) 2021
Paper
Code (WIP).




We present a method for estimating neural scenes representations of objects given only a single image. The core of our method is the estimation of a geometric scaffold for the object and its use as a guide for the reconstruction of the underlying radiance field. Our formulation is based on a generative process that first maps a latent code to a voxelized shape, and then renders it to an image, with the object appearance being controlled by a second latent code. During inference, we optimize both the latent codes and the networks to fit a test image of a new object. The explicit disentanglement of shape and appearance allows our model to be fine-tuned given a single image. We can then render new views in a geometrically consistent manner and they represent faithfully the input object. Additionally, our method is able to generalize to images outside of the training domain (more realistic renderings and even real photographs). Finally, the inferred geometric scaffold is itself an accurate estimate of the object's 3D shape. We demonstrate in several experiments the effectiveness of our approach in both synthetic and real images.
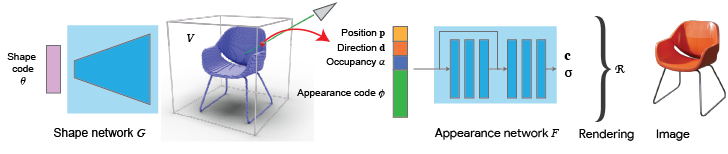
Our goal is to estimate Radiance Fields from a single image. To achieve this, we set up a generative process that maps latent codes of geometry and appearance to rendered images, all with the help of explicit (voxels) and implicit (neural radiance fields) representations. Let's dive into the individual components of our model:
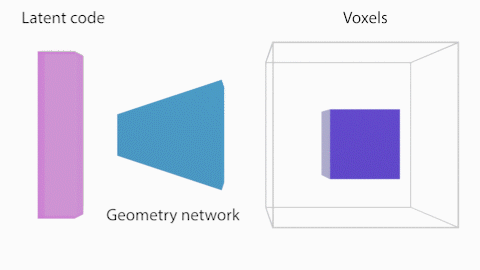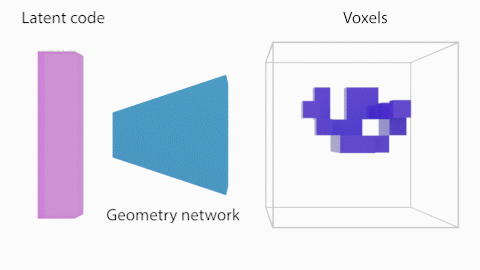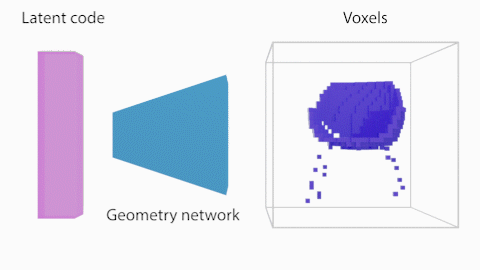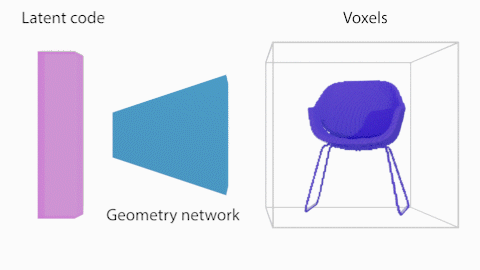
As a first step, we learn to generate voxels from latent vectors. This a supervised setup where we take the shapes of a ShapeNet class (eg chairs) and we learn a mapping between the latent vectors and the voxelized representation (128^3). The training is performed with several losses as described in the paper (eg weighted cross entropy, symmetry and projection losses), all inside a Generative Latent Optimization (GLO) framework, aka the latent codes are being optimized with the network parameters.
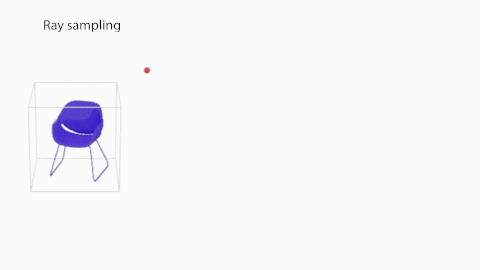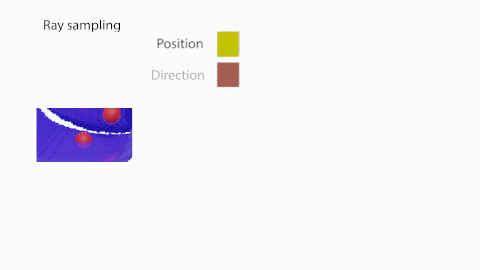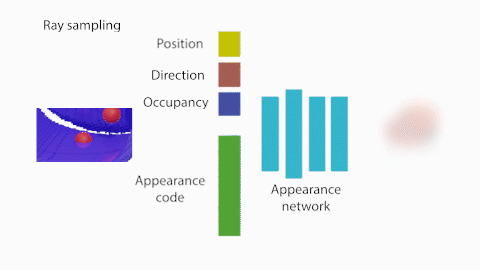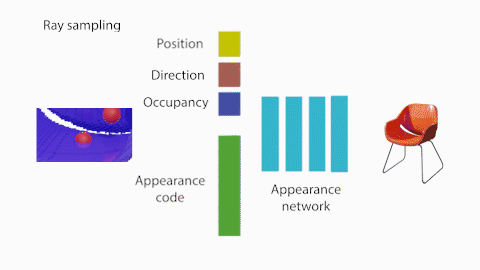
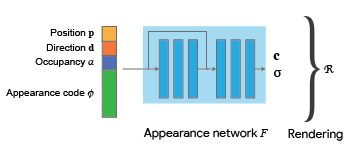
Secondly, we learn how to generate images using a NeRF-inspired model. Unlike the original NeRF formulation where there was a single network for a single scene, we want our model to be able to represent the radiance fields of many different objects. To do so, we condition the network with two additional inputs: the occupancy of every 3D point and a latent appearance code. In this way, the network learns to generate different radiance fields for different input shapes and appearances. Similarly as above, we train the appearance network using GLO (optimizing the MLP parameters together with the appearance codes) using L2 loss between the target and the rendered images. The rendering functions are the same as in NeRF. Note that the connection between the shape and appearance network is fully differentiable
Here is the interesting part: we can use the above model to estimate the radiance field from a single image together with its camera parameters (we show below how to estimate those as well). Once we estimate the radiance field, we can render arbitrary new views of the depicted object.


First we need to estimate the shape. In this illustration we show how things work for the ShapeFromMask approach but the procedure is the same also for ShapeFromNR. Given the mask and the camera parameters, we want to generate a voxel shape so when its rendered, it matches the mask. For this, we fine-tune the pretrained shape network and optimize together the latent code so the rendered generated shape fits the target mask.
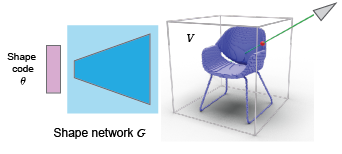

Finally, we estimate the radiance field that corresponds to the input image by fine-tuning the appearance network together with the appearane code. We want the output rendering to be as close as possible to the input image, so we use an L2 loss between the two.

Shape network. This network consists of 3 fully connected layers of size 512, followed by 7 layers of 3D transpose convolutions that map the intermediate features to a voxel grid of 128x128x128. The shape code θ has dimensionality of size 256 both for cars and chairs. The shape codes were initialized from a gaussian distribution. We use a batch size of 10, γ parameter for the weighted cross entropy was set to 0.8, the mirror weight was set to 0.9, and the projection weight to 0.01. The learning rate for the network parameters was 0.0001 and for the shape codes 0.001.
Appearance network. This network is similar to the original NeRF (Mildenhall et. al. 2020) and consists of 4 fully connected layers, concatenation of the intermediate features with the input features, and subsequent processing of another 3 fully connected layers. Each FC layer has size of 256. The size of the appearance code is 256 and it was initialized from a gaussian distribution. For the network, learning rate was set to 0.0001 and for the appearance code to 0.001.
Ray sampling. For every image in the training dataset we sample uniformly 128 rays. The near and far values are [1.25, 3.5] for Chairs and [0.5, 2.0] for Cars. We sample 128 points on each ray using stratified sampling and an additional 128 points using importance sampling (indicated by the geometric scaffold). We apply positional encoding for every point with 6 exponentially increasing frequencies.
Inference on a test image. For all variants we use 1024 uniformly sampled rays. We optimize the codes/networks for 500 iterations for ShapeNet-SRN, 1000 for ShapeNet-Realistic and 3000 for Pix3D. The learning rates are 0.0001 for the networks and 0.1 for the latent codes. The same parameters were used both for the appearance network and the shape network when applicable. To initialize the shape code, we used the code of the nearest training sample in the HOG space. The appearance code was initialized as the mean of all training appearance codes. For the qualitative results in ShapeNet-Realistic and Pix3D, we use also the mirrored input image during optimization. This results in more faithful free viewpoint renderings but it can produce amusing artifacts when the appearance symmetry does not hold (eg the price tag in the 4th row chair).
Here, we present animated results for real chairs from the Pix3D dataset.
| Input | Renderings | Input | Renderings |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
We demonstrate the effectiveness of our approach on real images of cars downloaded from the internet (taken from the PixelNeRF repository).
| Input | Renderings | Input | Renderings |
|---|---|---|---|
 |
 |
 |
 |
Here we present animations for chairs class from the ShapeNet-Realistic dataset.
| Input | Renderings | Input | Renderings |
|---|---|---|---|
 |
 |
 |
 |
More results on ShapeNet-Realistic
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Here, we visualize our renderings for the ShapeNet-SRN Chairs dataset.
| Input | Renderings | Input | Renderings | Input | Renderings |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
More results on ShapeNet-SRN-Chairs
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Finally, we visualize our renderings for the ShapeNet-SRN Cars dataset.
| Input | Renderings | Input | Renderings | Input | Renderings |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
More results on ShapeNet-SRN-Cars
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
@inproceedings{rematasICML21,
author = {Konstantinos Rematas and Ricardo Martin-Brualla and Vittorio Ferrari},
title = {Sharf: Shape-conditioned Radiance Fields from a Single View},
year = {2021},
booktitle = {ICML}
}